IT之家2月15日音信,科技媒体marktechpost昨日(2月14日)发布博文,报说念称加州大学伯克利分校的究诘团队建议了一种AI检修措施迪士尼彩乐园3总代,仅需少许数据即可增宏大言语模子(LLM)推理材干。
提高LLM推理材干的难点在于检修模子生成具有结构化自反念念、考据和回溯的长链式念念维(CoT)反映。现存模子的检修经由时常需要在广泛数据集上进行神秘的微调,且很多特有模子的检修措施并不公开。
究诘团队建议了一种新的检修措施,仅使用17000个CoT示例,微调Qwen2.5-32B-Instruct模子,并联贯了SFT和LoRA微调时间,强调优化推理体式的结构无缺性而非推行自身,通过矫正逻辑一致性并最大纵脱地减少毋庸要的臆想支拨,从而显耀提高了LLM的推理效用。

究诘标明,在增强LLM推感性能方面,CoT的结构起着至关紧迫的作用,编削检修数据的逻辑结构会显耀影响模子的准确性,迪士尼彩乐园手机旧版而修改单个推理体式的影响则很小。

IT之家附上使用新措施后的测试效果如下:
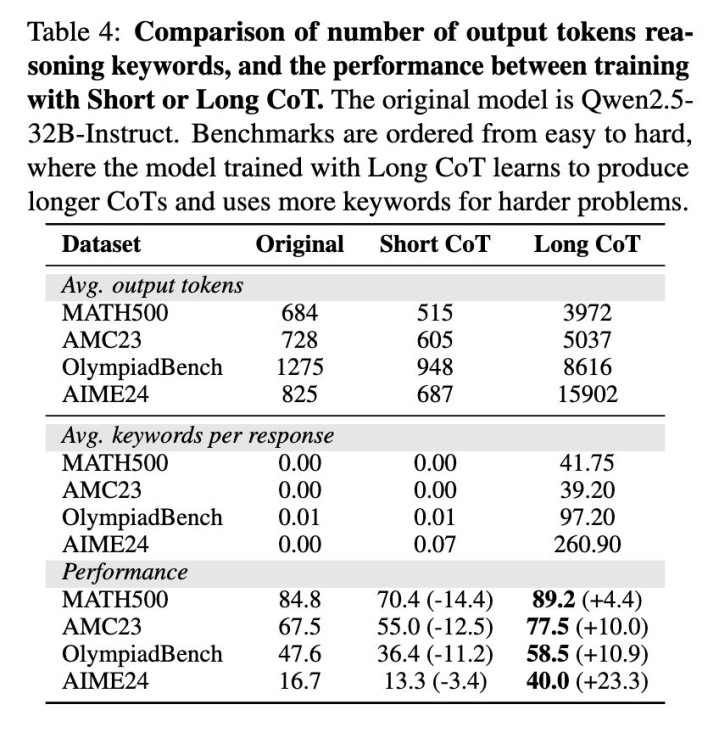
AIME2024:准确率达到56.7%,提高了40.0个百分点。
LiveCodeBench:得分57.0%,提高了8.1个百分点。
Math-500:达到90.8%,提高了6.0个百分点。
AMC2023:达到85.0%,提高了17.5个百分点。
OlympiadBench:达到60.3%,提高了12.7个百分点。
这些收尾标明,高效的微调时间不错使LLM在更少的数据需求下达到与OpenAI的o1-preview等特有模子相忘形的推理材干。
这项究诘标明,将关切点从大限制数据依赖转向结构无缺性,不错建树出一种以最少的臆想资源确保宏大逻辑一致性的检修措施。这种措施减少了对海量数据集的依赖,同期保执了宏大的推理材干,使LLM更易于拜谒和扩张。
该究诘的效果为异日模子的优化铺平了说念路,评释结构化微调政策不错灵验地增强LLM推理材干迪士尼彩乐园3总代,而不会影响效用,这标记着复杂的AI推理模子在更粗拙欺诈方面迈出了紧迫一步。